- Google начал как поисковая система
- Для более качественных серверных поисковых запросов Google нужны данные, много данных
- Как Google использует Hummingbird и Knowledge Graph для лучшего понимания поиска
- Как Hummingbird и Knowlege Graph изменили и сформировали поиск - это начало семантического поиска
- С семантическим поиском приходит сущность
- Что это значит для маркетологов
- Будут ли мгновенные ответы Google отбирать трафик у маркетолога?
- SEO стратегия для эпохи семантического поиска

Google начал как поисковая система
«Организовать мировую информацию и сделать ее общедоступной и полезной».
Это цель Google как компании. Несмотря на их предприятие в другие технологии. От производства смартфонов до того, чтобы быть основным поставщиком цифровой рекламы. Корень Google связан с поиском, а поиск - с данными и намерениями пользователей.
96% Доход Google исходит от рекламы. Около 70% из AdWords и остальные из AdSense. Google воспользовался своим положением поисковой системы и предлагал рекламные ролики в соответствии с их сложным алгоритмом.
Это возможно из-за их огромного охвата аудитории и впоследствии данных, которые они могут собирать.
Теперь, как работает поиск?
Он начинается с сканирования до рендеринга тех, которые требуют рендеринга, а затем индексации. Когда пользователь нажимает ввод для запроса, множество алгоритмов, работающих на огромном количестве машин, обрабатывают и фильтруют свою библиотеку индексированных данных, чтобы предоставить пользователю список. Список того, что, по его мнению, хочет пользователь.
Google теперь эквивалентен глаголу поиска . Вы говорите «позвольте мне посмотреть это» или вы говорите «позвольте мне Google это» или, возможно, вы говорите «эй, Google, что такое…» ? Вы, я и они, мы все полагались на Google, когда нам нужна информация, когда нам нужен ответ.
К счастью (или, к сожалению, для Google), все еще существуют страны, где Google не является предпочтительным поисковым гигантом. У вас есть Baidu в Материковая часть Китая где Google попытался вступить, а потом отступил. Или Яндекс в России, который является пятым по величине поисковиком в мире. В то время как Naver и Daum доминируют в корейском интернете.

Несмотря на доминирование Google, все еще есть некоторые поисковые системы, которые предпочитают в своей стране. Нравится яндекс для россии.
Несмотря на небольшие неудачи в локализации Google все еще имеет железную хватку во многих странах.
Для более качественных серверных поисковых запросов Google нужны данные, много данных
Почему это касается нас? Что ж, это касается каждого пользователя Интернета, потому что это означает, что у Google есть доступ к миллионам и миллиардам данных. Со всего мира на разных языках и разных темах.
Google создает огромную и, возможно, самую большую виртуальную библиотеку. Они достигают этого, активно выкладывая контент по всему миру. Они активно получают все больше контента и технологий обработки контента.
Они не только хотят собирать содержимое и данные, но и пытаются понять их. Вот почему они приобрели семантическую поисковую компанию, как Metaweb , Технологическая компания Natural Language Processing Wavii , Они также отслеживание поведение пользователей на таких платформах, как Gmail, YouTube, даже история поиска в зависимости от вашего поведения в Интернете.
Они собирают данные, как драконы собирают драгоценные камни. Зачем Google нужны эти данные? Почему драконы собирают драгоценные камни для? Возможно, жадность, да, это может быть жадность. Но они делают это во имя понимания намерений пользователя.

Google собирает данные, как дракон собирает драгоценные камни.
Миллионы фрагментов данных, которые связаны с каждым ключевым словом, которое часто ищут люди, используются для расшифровки цели запроса, основываясь на их доступе к большому пулу легкодоступного содержимого.
Пул данных служит базой для их службы поиска, не забывая рекламу, и кто знает, для чего они используют данные? Они просто не говорят тебе эксплицитно ,
Все это сделано, чтобы помочь им лучше проанализировать и точно определить намерения пользователя. Google хочет знать, чего именно хотят пользователи. Затем подайте его им на серебряной тарелке, как только будет сделан запрос в поиске Google. Они хотят порадовать пользователей. Счастливые пользователи, счастливее гугл ,
Как Google использует Hummingbird и Knowledge Graph для лучшего понимания поиска
Вам известно, что Google подписал контракт с Пентагоном на Project Maven? ИТ-гигант оказывает помощь в создании оружия для беспилотников, предоставляя им технологию для самообучения машин.
Видите ли вы, насколько передовая технология искусственного интеллекта Google заключается в том, что даже Пентагон обращается к ним за помощью?
Теперь, как это касается поиска? Вы видите, как я уже упоминал ранее, поиск связан с двумя вещами. Данные и человеческие намерения. Чтобы понимать данные так, как они соответствуют человеческим намерениям, машины должны имитировать мыслительный процесс человека.
И одна вещь, которую машинам трудно понять, это сложность и тонкость языка.
Обновление Hummingbird, выпущенное еще в 2013 году, которое стало крупнейшим обновлением для поисковой системы с 2001 года, позволило существенно улучшить работу поиска. Используя и включив теорию семантики в свои алгоритмы, они открыли новый путь в мир поиска.
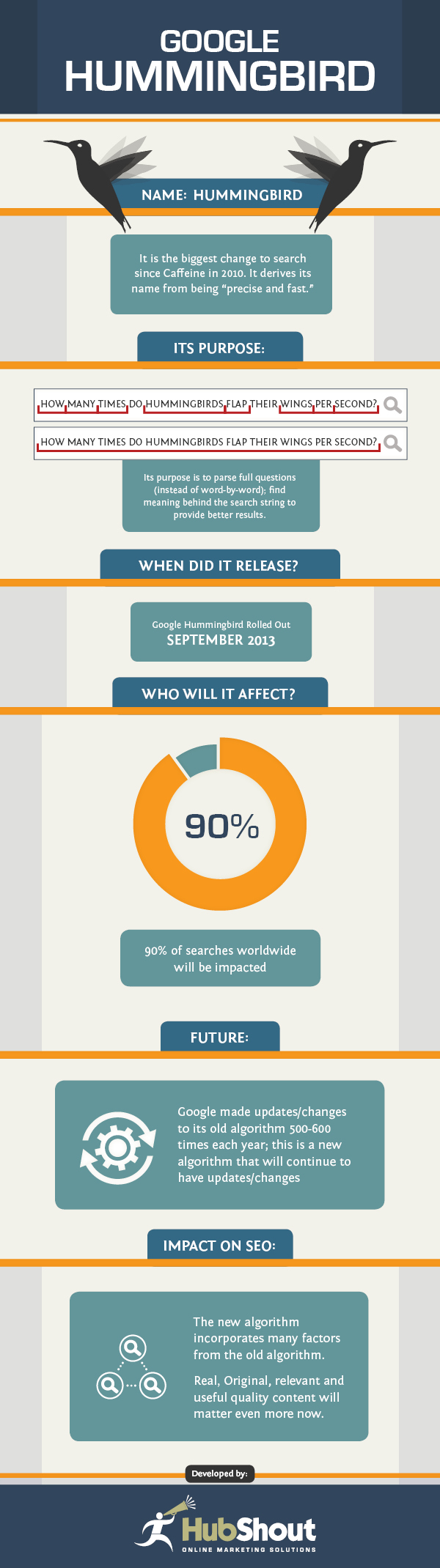
Обновление Google Hummingbird с первого взгляда.
Этот новый путь приводит к тому, что Google понимает намерения пользователей гораздо более свободно. Поиск теперь стал еще на один шаг ближе к тому, чтобы задать Google вопрос, а не вводить ключевые слова, которые, как вы хотите, дадут вам желаемый результат.
В то время как граф знаний был в игре немного дольше, чем обновление Hummingbird, кажется, что понимание того, что на самом деле граф знаний Это всегда было немного грязно.
Это может быть небольшая графическая карта знаний, которая отображается справа как динамическая функция страницы результатов поиска (SERP). Это дает пользователям краткий обзор искомого термина. Информация, используемая для графической карты знаний, обычно берется из нескольких некредитованных источников.
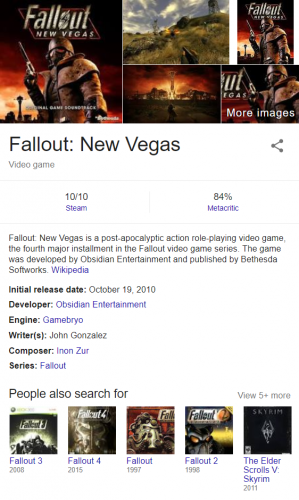
Графическая карта знаний Google дает пользователям мгновенный ответ, не покидая страницу результатов.
Но граф знаний также может быть пулом данных. По сути, это база данных, которая собирает миллионы фрагментов данных о ключевых словах, которые люди часто ищут во Всемирной паутине, и о намерениях, стоящих за этими ключевыми словами, на основе уже доступного контента.
Google всегда делает упор на пользовательский опыт и ищет способы помочь создать то, что, по их мнению, будет полезно для пользователей. От продвижения проекта AMP для более быстрого мобильного просмотра до лучший стандарт рекламы где ненавязчивая реклама отмечается.
Как они могут убедиться, что они обслуживают пользователей правильно? Получая больше данных и следя за тем, чтобы они правильно анализировали данные.
График знаний «… подключается к коллективному интеллекту Интернета и понимает мир немного лучше, чем люди».
График знаний - это база данных Google, а алгоритм Hummingbird - это мозг, пытающийся разобраться в этом.
«Везде, где мы можем получить структурированные данные, мы добавляем их», - сказал Сингхал из интервью с Search Engine Land о графе знаний.
Как Hummingbird и Knowlege Graph изменили и сформировали поиск - это начало семантического поиска

Поиск раньше работал на основе ключевых слов и буквального значения ключевых слов. Строка слов не имеет значения, как для людей и машин. Человек устанавливает связь между словами и естественным образом формирует полное значение. В то время как машина вытягивает буквальное значение каждого отдельного слова без отношения процесса.
Это не так, как мы, как люди, работаем.
Человеческий разум подсознательно хранит информацию, которая позже служит ключом к новой части информации, чтобы связать их в отношения. Мы постоянно собираем кусочки головоломки, чтобы создать большую картину. Это то, что Google хочет подражать.
Собранные и проиндексированные данные являются информацией, в то время как отслеживаемое поведение человека помогает создать контекст для запроса и, наконец, алгоритм - это сети, пытающиеся связать их все вместе, используя подсказку, которая является словом, введенным в поле запроса, чтобы понять намерения пользователя и дайте им то, что Google считает наиболее подходящим.
Google жаждет данных, потому что это источник их знаний. Единственный способ лучше обслуживать пользователей - это понимать их. Поймите их так же близко, как люди понимают друг друга.
С семантическим поиском приходит сущность
Поиск семантики представил новый способ анализа данных. Который включает в себя теорию семантики и, скорее всего, использует модель семантического знания.
Что такое модель семантического знания ? Проще говоря, модель семантического знания описывает, что означают данные, и показывает, где они находятся среди других. Поэтому помогает определить связь между различными частями данных.
Куски данных называются объектами. Сущность - это вещь, физическая или концептуальная. Каждая сущность имеет атрибуты и характеристики, которые затем сопоставляются и соотносятся с характеристиками других сущностей, чтобы понять их отношения.
Это необходимо, потому что большинство слов содержат несколько значений, которые означают разные вещи, когда вставляются в различный набор слов в зависимости от контекста.
Подобно тому, как человек естественным образом понимает набор слов, сгруппированных воедино, модель семантического знания помогает поисковой системе осмысленно воспринимать набор слов, введенных в строку поиска.
Модель также используется, когда Google пытается решить, какой контент извлечь из своей библиотеки, чтобы вернуть поисковый запрос.
На самом деле, кроме «нормальной» индексированной базы данных, у Google есть отдельная база данных, которая называется связанные лица индекс базы данных.
Сущность больше не просто слово или вещь. Под сущностью понимается и определяется ее диапазон характеристик и атрибутов. Более склонны к тому, как человек воспринимает слово, а не как тезаурус.
«Вы узнаете слово по компании, которую оно хранит». (Firth, JR 1957: 11)
Давайте посмотрим на это так, сущность - это когда слово понимается, включая здравый смысл, который его окружает.
Веселый - это фрукт, он сладкий, у него есть семя. Это основная информация, которую знает как компьютер, так и человек. Но одна вещь, которую компьютер может не знать, а человек узнает, - это история о том, как Джордж Вашингтон срубил вишневое дерево (или нет, очевидно, это миф ).
Человек обрабатывает информацию гораздо сложнее, чем машины.
И это то, что отличает хорошую поисковую систему от отдельной поисковой системы. Способность понимать слово как сложную сущность, а не просто его словарное определение.
Внезапно, как контент может ранжироваться, когда ключевое слово упомянуто минимально, или текст на самом деле длинный и утомительный для чтения, и не так много картинок разбрызгивается, имеет смысл.
Оптимизация на странице может сделать очень многое, только когда Google больше не смотрит на это.
Что это значит для маркетологов
Помимо широко известной плотности ключевых слов и обратных ссылок, связанные с ними объекты теперь являются еще одним фактором, который необходимо учитывать.
Это означает, что оптимизация ключевых слов латентного семантического индексирования (LSI) теперь актуальна как никогда.
Ключевые слова LSI в смысле поиска информации используют скрытый семантический анализ (LSA) для создания набора тем или, в данном случае, набора ключевых слов, который соответствует документу путем анализа упомянутых слов. Результатом является набор концептуально похожих ключевых слов.
Гипотеза о распределении предполагает, что набор ключевых слов LSI будет естественным образом отображаться в документе или в нескольких похожих тематических документах. Эти ключевые слова или объекты являются одним из факторов, которые Google, возможно, использовал для определения релевантности контента.
Google подтверждает, что они отслеживают связанные сущности в Интернете с помощью базы данных связанных сущностей. Это означает, что страницы содержания в Интернете теперь также связаны со связанными объектами.
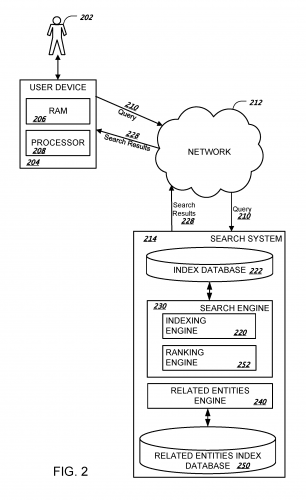
У Google есть и база данных индексов, и база данных индексов связанных объектов.
От этого могут избавиться создатели контента и маркетологи: держите своих друзей ближе, а врагов - ближе.
Когда вы думаете о теме, которую вы хотите расширить, посмотрите, что написали ваши конкуренты. Потому что они будут вашими родственниками. Содержимое, которое они вылили, является частью того, что Google делает из этой темы.
Теперь также время для вас, чтобы серьезно отнестись к поиску. У Google есть пулы данных и несколько способов, которые они могут использовать для отслеживания поведения пользователей, чтобы найти то, что пользователь действительно хочет. Мы должны сделать то же самое.
Будут ли мгновенные ответы Google отбирать трафик у маркетолога?
«Кроме того, у пользователей могут возникнуть вопросы о сущности после отправки запроса, направленного на эту сущность, и информация о сущностях, которые являются ответами на эти вопросы, может быть предоставлена пользователю как часть ответа на запрос…»
Веб-мастера и авторы контента обеспокоены тем, что с появлением функций SERP, направленных на предоставление пользователям мгновенных ответов, их рейтинг кликов пострадает.
Согласно HubSpot, содержание, показанное в избранном фрагменте, который занимает нулевой ранг, на самом деле имеет примерно вдвое большую долю кликов по сравнению с обычными результатами с синими ссылками.
Люди обеспокоены тем, что однажды Google станет самодостаточным с графиком своих знаний и создатели контента больше не нужны.
Ну, я думаю, что если в тот день, когда машина сможет сформулировать свое собственное первоначальное мнение по теме, а не выступать в роли куратора информации, авторы контента не умрут.
Зачем? Давайте еще раз посмотрим на миссию Google.
Они хотят, чтобы «организованная информация была полезной и доступной»
Google организует информацию? Только когда создатель дает им понять, что такое часть контента.
Может ли Google генерировать информацию без участия человека? Нет.
Кто тот, кто считает что-то полезным или нет? Человек.
Как информация может быть доступна? В цифровых сетях, созданных человеком.
Технология рождается из собранной человеческой мудрости, предназначенной как инструмент для служения людям. Они являются посредниками передачи информации от одного человека к другому. Так что нет, Google не захватит мир. Во всяком случае, не в смысле создания контента.
SEO стратегия для эпохи семантического поиска
Давайте спланируем стратегию, используя миссию Google в качестве ориентира.
1. Убедитесь, что ваш сайт выглядит организованным как для сканеров, так и для пользователей.

Структурированные данные - это то, что помогает Google идентифицировать сущности, присутствующие в вашем контенте.
Старайтесь использовать метаданные и разметки везде, где вы можете общаться со сканерами и индексаторами.
Читатели могут сразу понять, что Гомер Симпсоны это имя. Но без правильной разметки поисковая система не получит ее.
Схема действует как тег, который сообщает поисковой системе, какая часть вашего контента что означает.
Это стандартная и широко используемая форма микроданных, созданная совместными усилиями Google, Yahoo, Bing и Yandex. Когда вы видите, что все эти громкие имена выстроены в ряд, это означает, что вам лучше обратить на них внимание.
Существует обширный список типов элементов, которые вы можете использовать. Ниже приведены некоторые полезные и более общие наценки, которые могут быть вам полезны (просто вам не нужно проходить через библиотека сам).
- Что это?
- http://schema.org/Place
- http://schema.org/Person
- http://schema.org/Corporation
- http://schema.org/Product
- http://schema.org/gender
- http://schema.org/birthDate
- http://schema.org/address
- http://schema.org/email
- http://schema.org/jobTitle
- http://schema.org/Blog
- http://schema.org/Article
- http://schema.org/HowTo
- http://schema.org/Review
- http://schema.org/SoftwareApplication
У вас есть дополнительная информация об этом?
Что это за контент?
Что является первым фактором, который заставляет вас принять решение остаться, прочитать статью или вообще покинуть страницу?
Ну, для меня это так легко читать. Блоки текста могут быть немного пугающими и скучными. Хотя слишком много картинок может отвлекать. Если за мной, когда я прокручиваю страницу вниз, обычно следует огромный рекламный блок, я обычно просто сдаюсь.
Будьте организованы не только для машины, но и для читателей. Убедитесь, что вы структурируете свое содержимое четко и ожидаемым образом.
- Ваше содержание в коротких параграфах?
- Используете ли вы патроны, ящики и нумерацию очков, где это возможно?
- Вы предлагаете похожие картинки, чтобы продемонстрировать свои очки?
- Есть ли навязчивая реклама, которая мешает чтению?
- Сегментировано ли содержимое в соответствии с темой?
- Ваш шрифт хорошо контрастирует для чтения с цветом фона?
- Ваш шрифт достаточно большой, чтобы его было удобно читать?
2. Создайте полезное содержимое, соответствующее поисковому замыслу
Я думаю, что полезное должно быть сформулировано более конкретно как полезное для пользователей. В словах создателей контента, часть контента должна соответствовать цели поиска.
Есть несколько способов добиться этого. В первую очередь, золотое правило SEO - проводите исследования ключевых слов.
Я знаю, что только что подчеркнул важность сущностей, но не запутайтесь, потому что ключевое слово - это тоже сущность.
Узнайте, что ищут ваши целевые пользователи. Что их беспокоит? Что их возбуждает? Какую информацию они хотят узнать? Для этого вам нужно собрать данные.
- Используйте планировщик ключевых слов в Google AdWords.
- Используйте keywordtool.io, чтобы получить больше ключевых слов.
- Используйте LSIGraph, чтобы повысить актуальность игры
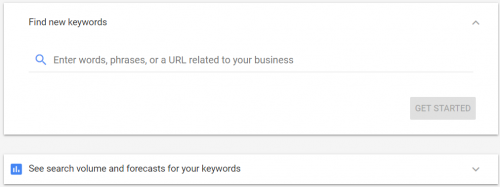
Он покажет вам объем поиска ваших целевых ключевых слов, а также прогнозировать, как он будет работать. Все эти данные, конечно же, принадлежат Google.
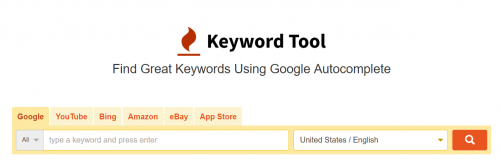
это Фримиевый инструмент может быть хорошим местом для ваших идей ключевых слов длинный хвост. Несмотря на то, что в нем отсутствует функция объема поиска, другой сайт, на который она нацелена, например, Google, Youtube и Bing, предлагает более широкий выбор кандидатов на ключевые слова.
это Инструмент подсказки ключевых слов LSI дает вам список тематически связанных ключевых слов с вашим целевым ключевым словом. Посмотрите, сколько вы можете ударить или использовать его в качестве руководства, чтобы увидеть, насколько актуальна ваша фигура в глазах машины.
Вы можете оценить эффективность вашего контента, посмотрев данные об опыте пользователя.
Слишком высокий уровень отказов? Или, может быть, время на странице слишком мало. Все это может помочь вам составить представление о том, насколько актуальна тема для пользователей.
Гугл Аналитика это простое место для начала.
Сделайте изменения в своих частях, если у них есть потенциал, но данные просто не совпадают.
Люди в наше время хотят все быстро, быстрые машины, быстрая скорость интернета, быстрая информация.
Вот почему во время процесса создания стремиться к тому, чтобы представлять наибольшую информацию самым прямым способом. Google любит инструкции и списки. Вы можете часто видеть те, которые помещены как показанный фрагмент.
- как
- инфографика
- таблицы
- вещи, которые могут дать им больше информации с первого взгляда
Конечно, есть и на другом конце спектра. Есть люди, которые читают длинные фрагменты. Такого рода люди хотят получить подробную информацию.
- исследования
- отзывы
- понимание
- анализ
- руководство
Дайте вашей аудитории здоровое посыпание обоих.
3. Убедитесь, что ваш сайт доступен как сканерам, так и пользователям.
Доступный приходит во многих отношениях и формах. В скорости загрузки вашей страницы, сколько акций у вас есть.
Доступность - это не просто размещение чего-либо в Интернете и надежда, что люди это увидят.
Машины должны поднять его, прежде чем они станут мостом между вами и читателями.
В случае с SEO, первое, что вам нужно сделать, это предоставить доступ сканерам. Затем, конечно, убедитесь, что они действительно могут интерпретировать ваш HTML, чтобы понять ваш контент.
- Убедитесь, что ваши роботы настроены правильно
Чтобы разрешить доступ всем сканерам по всему миру:
Пользователь-агент: *
Disallow:
Значение по умолчанию для разрешения индексации и доступа к ссылкам на странице должно быть:
META NAME = «ROBOTS» CONTENT = «INDEX, FOLLOW»
Для JavaScript-сайтов рендеринг может быть проблемой.
Если ваш сайт работает на JavaScript, поисковой системе может потребоваться больше времени для индексации вашей страницы. Хотя Google подтверждает, что они могут сами отображать страницы для правильного индексирования JavaScript, это не идеально.
Google рекомендует веб-мастерам реализовать гибридный и динамический рендеринг, чтобы упростить процесс индексации. Однако это не обязательно.
Принимая во внимание ресурсы, необходимые для обработки рендеринга, вам может потребоваться дважды подумать, прежде чем реализовывать какие-либо.
Но использование веб-сайта с поддержкой JavaScript может на самом деле повысить доступность для пользователей благодаря функции сервисного работника и тому факту, что все выбирается динамически.
Более высокая скорость загрузки делает ваш контент более доступным.
Не у всех есть подключение к интернету через оптоволокно. 3G все еще очень широко используется и достаточно полезен для большой части населения. Вот почему наличие раздутый сайт не собирается добавлять очки к вашей доступности.
Раздутый HTML-код также может замедлить работу вашего веб-сайта, что затруднит получение того, что вы предлагаете.
Посмотрите, как ваша скорость загрузки выполняет с помощью Google PageSpeed Insights ,
Распространите свое содержание по нескольким сайтам.
Поиск в Google не обязательно должен быть единственным местом, где люди могут наткнуться на ваш контент. Вы можете взять на себя инициативу поделиться своим контентом на нескольких платформах.
Гостевая публикация на других сайтах вашей же ниши может быть очень полезной. Для одного вы можете охватить другую аудиторию, он также устанавливает название вашего бренда. Помните связанные объекты, о которых мы говорили? Упоминание на другом веб-сайте, даже без ссылки на вас, может помочь вам повысить свою актуальность в этой нише.
Есть люди, которые любят картинки больше, чем слова и наоборот. Зачем жертвовать своим охватом аудитории обоих типов, будучи только одной? Конвертируйте ваш контент в несколько форматов.
Вы можете создать стопку слайд-шоу из вашего контента и поделиться им на сайтах, таких как slideshare.com, и получить в два раза больше. Или создайте инфографику на основе своего исследования, чтобы само изображение могло иметь более высокий рейтинг в изображении Google по сравнению с вашим блоком текста.
Quora - это отличное место, где можно разобраться и установить авторитет. Смотрите вопрос, где ваш последний пост в блоге является идеальным ответом? Ответьте на вопрос, сняв отметки с вашего текста и добавив ссылку на вашу страницу.
Будьте изобретательны и проявите инициативу, чтобы сделать ваш контент доступным для совместного использования.
Полиглот упал в глубокий синий мир SEO и въездного маркетинга, вооруженный пылкой страстью к письмам и увлечением тем, как все крутится во всемирной паутине.
Теперь, как работает поиск?Зачем Google нужны эти данные?
Почему драконы собирают драгоценные камни для?
Пул данных служит базой для их службы поиска, не забывая рекламу, и кто знает, для чего они используют данные?
Видите ли вы, насколько передовая технология искусственного интеллекта Google заключается в том, что даже Пентагон обращается к ним за помощью?
Теперь, как это касается поиска?
Как они могут убедиться, что они обслуживают пользователей правильно?
Будут ли мгновенные ответы Google отбирать трафик у маркетолога?
Зачем?
Может ли Google генерировать информацию без участия человека?