Вот вторая статья, которую я поместил в своем первом информационном бюллетене.
В этой статье я расскажу, что такое A / B-тестирование (также называемое сплит-тестированием). Затем я немного расскажу об одноруких бандитах, что является более статистическим методом.
адаптирован как A / B тестирование, чтобы делать то же самое или почти, но лучше. Часть этой статьи - обложка одного из моих постов в этом блоге (большое повторное использование).
A / B-тестирование позволяет вам выбирать из нескольких модификаций вашего сайта, которые позволят максимально увеличить определенный критерий (коэффициент конверсии, продолжительность посещения и т. Д.). Концепция A / B-тестирования совершенно глупа: речь идет о случайном разделении посетителей на несколько групп и предоставлении каждой группе различного пользовательского опыта. Группа будет называться контрольной группой (группа A), она состоит из посетителей вашего сайта, которые будут перемещаться по классическому сайту. Другая группа с рейтингом B будет иметь другую версию сайта. Для каждой из его групп мы измеряем критерий. Версией вашего сайта, которая дает наилучшее значение критерию, является та, которую вы поставили на место.
Чтобы лучше понять, что такое A / B-тестирование, давайте рассмотрим пример. Представьте, что у вас есть сайт по продаже книг, и что кнопка «Купить» - это глупая кнопка со словом «Купить» на черном фоне. Хотите знать, если щелкнув текст «Купить» неоновым цветом, вы получите лучший рейтинг кликов. Для этого вы проведете A / B тест: 90% ваших посетителей остаются с классической кнопкой, в то время как 10% имеют кнопку с мигающим текстом флуоресцентного зеленого цвета. Вы немного подождете, а через некоторое время посмотрите на результат. например, у вас было 10 000 посетителей, и результаты следующие:
- Группа A: 9000 VU, 180 кликов (2%)
- Группа B: 1000 VU, 10 кликов (1%)
Естественным выводом будет ваш: я держу кнопку такой, какая она есть, потому что ставка лучше.
Однако вы можете ошибиться, заключив, что один из вариантов лучше другого, в то время как различие может быть связано с вполне нормальным изменением случайных величин. Это происходит в очень хорошо отмеченном случае: тот, где размер выборки слишком мал, так что в случае разницы низких значений по критерию мы можем сделать существенный вывод. Поэтому необходимо поставить под сомнение минимальный размер выборки .
Все это история точности и доверия. Мы хотим достаточно точно оценить значение, полученное для каждой из возможностей. Представьте, что критерий отмечен 

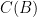

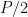

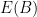

Это конечно то же самое

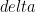

как правило, 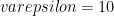
Есть ли формула, которая дает размер выборки на основе
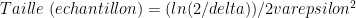
Например, если дельта = 5%, а эпсилон = 0,5%, мы получаем 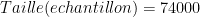
Что важно помнить о A / B-тестировании, это то, что это метод, который позволяет вам выбирать между несколькими альтернативами, оценивая влияние выбора на количественный критерий. Существует много проблем с реализацией: для того, чтобы заключение было обоснованным, изучаемые возможности должны предоставляться посетителям случайным образом, гипотезы должны быть некоррелированными и т. Д. Но еще одним препятствием является то, что A / B-тестирование - это один выстрел / 2 шага. Один выстрел, потому что если вы хотите добавить больше маршрутов в ходе дополнительных предположений, он начнется заново. И 2 шага, потому что есть фаза исследования, затем фаза использования результата. Что кажется более разумным, так это алгоритм, в котором я составляю список гипотез, которые необходимо рассмотреть, и в то же время выбираю лучшие гипотезы или предположения, использую их и позволяю добавлять новые.
Ну, этот алгоритмический метод существует. Это метод бандитов пингвинов. Который я обрисую здесь принцип. Существуют две основные функции метода: может быть столько параметров, сколько вам нужно, и вы можете добавлять или удалять параметры в режиме реального времени.
Имя одноруких бандитов происходит от мира казино. Представьте, что вы находитесь перед несколькими машинами. Какова ваша стратегия, чтобы выиграть как можно больше? Что вам нужно сделать, так это чаще всего играть на машинах, которые приносят вам наибольшую прибыль, и время от времени пробовать другие машины, чтобы увидеть, не начнут ли они создавать отчеты. Этот процесс, который называется разведкой - эксплуатацией, является сердцем техники бандитов-пингвинов.
На следующем рисунке обобщен метод:

Когда посетитель попадает на сайт, вы случайным образом рисуете между исследованием и эксплуатацией. Здесь я положил 10%, но на практике это значение начинает увеличиваться (например, 50%), чтобы быстро проверить все гипотезы, а затем уменьшается, чтобы максимизировать использование. Когда мы находимся в фазе исследования, мы случайным образом рисуем одну из гипотез и обновляем значение соответствующей меры (например, рейтинг кликов). Находясь на этапе эксплуатации, пользователю предоставляется лучшая гипотеза.
По мере увеличения количества посетителей значения каждой гипотезы, рассчитанные с использованием бандитов пингвинов, приближаются к истинным значениям. Конечно, я опускаю все технические аспекты, но вы также можете помнить, что важным является управление соотношением разведка и эксплуатация. Поддержание постоянной ставки (например, 10%) - это то, что мы называем стратегией
Существуют гораздо более сложные и эффективные стратегии, но в контексте веб-приложения их бесполезно использовать.
В заключение напомню, что метод бандитских пингвинов имеет только преимущества. Она работает постоянно, как для разведки, так и для эксплуатации. Мы можем добавлять и удалять гипотезы навсегда. И, наконец, он адаптируется к изменениям: ваша аудитория меняется, метод обнаруживает и адаптируется.
Вы хотите узнать, как сделать вас однорукими бандитами, мастер-класс Stats + WEB есть для этого!
Какова ваша стратегия, чтобы выиграть как можно больше?