- Транскрипція відео про Robots.txt і основний рівень мета-роботів [Версія липня 2017]
- Що таке Robots.txt? [Другий 52]
- Що таке використання Robots.txt?
- Що таке мета-роботи? [Хвилина 2:00]
- Що вказує на кожну з цих позначок?
- Практичні приклади [хвилин 3:00]
- Аналіз мета-роботів з кричущою жабою [хвилина 4:56]
- Приклади Robots.txt [Хвилина 6:26]
- # 2 - Які комбінації мета-роботів можна зробити?
- # 3 - Отже, яка велика різниця між Robots.txt і мета-роботами?
- Висновок
Скільки разів ви запитували себе, яка різниця між файлом robots.txt і тегом мета-роботів ? Хоча вони подібні, вони мають різні функції. Сьогодні Іван Торренте зробить це дуже чітко в цьому відео.
Завдяки цьому SEO навчання Ви отримаєте знання для поліпшення бюджету сканування мережі або часу, який Google призначає своїм роботам для відстеження сторінок веб-сайту.
Крім того, у відео є приклади файлів robots.txt і таких інструментів, як Screaming Frog, за допомогою яких можна проаналізувати в секундах ярлик мета-роботів широкого набору сторінок.
Настав час. Хіт гри і насолоджуйтеся!
Транскрипція відео про Robots.txt і основний рівень мета-роботів [Версія липня 2017]
Хочете мати весь вміст відео в письмовому вигляді? Тут у вас є і з розширеннями!
Не втрачайте жодних деталей тренінгу, наданого нашим партнером у цьому відео, до якого ми додали деякі часті запитання та дані, які підсилюють вивчення цих ключових понять у веб-позиціонуванні.
Привіт, друзі SEO! Я Іван Торренте, консультант в команді Webpositer. У сьогоднішньому відеоролику ми будемо знати, як покращити бюджет сканування, бюджет сканування пошукової системи за допомогою robots.txt і метароботів. Давайте!
Що таке Robots.txt? [Другий 52]
![[Другий 52]](/wp-content/uploads/2019/12/uk-ot-robotstxt-i-meta-robots-u-comu-riznica-1)
Перше, що я поясню в сьогоднішньому відео, це те, що є robots.txt.
Це файл, який висить з кореня нашого домену , зазвичай це назва нашого домену, панель robots.txt.
ПРИКЛАД -> mydomain.com/robots.txt
+ INFO:
Файл robots.txt - це спосіб запобігання певним роботам, які аналізують веб-сайти або інші роботи, які досліджують весь або частину доступу веб-сайту до додавання непотрібної інформації до результатів пошуку .
Robots.txt, також відомий як протокол виключення роботів, складається з текстового файлу, який потрібно вставити в основну папку вашого веб-сайту , метою якого є повідомити роботам Google, які URL-адреси ми хочемо індексувати, а які ми хочемо, щоб вони опускалися і тому не зберігалися в базі даних Google або відображалися в результатах пошуку.
Що таке використання Robots.txt?
Цей файл використовується для блокування будь-яких каталогів або URL-адрес, які ми не хочемо сканувати пошуковою системою і не витрачають час. Таким чином, ми збережемо бюджет відстеження, відомий бюджет сканування, щоб він був присвячений іншим важливим URL-адресам.
+ INFO:
Використання цього файлу необхідно для того, щоб уникнути індексації тих сторінок, які ми не хочемо враховувати Google , що унеможливлює їх відстеження, а отже, і їх індексацію. Без присутності файлу robots.txt роботи будуть сканувати весь ваш веб-сайт і індексують усі URL-адреси, які знаходяться на вашому шляху.
Роботи Google перед початком пошуку шукатимуть файл robots.txt, щоб дізнатися маршрут, який їм слід слідувати , тому важливо чітко вказати у файлі ті URL-адреси, які ми хочемо індексувати, і ті, що не мають.
Тут ми працюємо з директивою Disallow . Це може бути з параметрами, замовленнями або фільтрами, це залежить. Наприклад, в WordPress ми можемо заблокувати типовий wp-admin, ми можемо заблокувати для prestashop порядок або відфільтрувати, якщо у нас є диференціації в межах категорій. Ми будемо блокувати все це, щоб не мати дубльований вміст немає URL-адрес
Важливо знати, що файл robots.txt є одним з найбільш читаних пошуковою системою , тому ми повинні вказати, де знаходиться файл . sitemap ,
Ми зробимо це в нижній частині файлу robots.txt, який зазвичай є midominio.com/sitemap.xml .
Що таке мета-роботи? [Хвилина 2:00]
![[Хвилина 2:00]](/wp-content/uploads/2019/12/uk-ot-robotstxt-i-meta-robots-u-comu-riznica-2)
Мета-роботи - це тег HTML, який зазвичай з'являється у верхній частині кожної URL-адреси. Кожна URL-адреса нашого веб-сайту повинна мати різні мета-роботи, залежно від того, що нас цікавить. Їх можна позначити як Індекс / Індекс або Ніколи слідувати / слідувати .
+ INFO:
Тег мета-роботів повідомляє Google, які сторінки нашого веб-сайту не хочуть індексувати або відображатися в результатах пошуку.
Він працює подібно до файлу robots.txt, з особливою особливістю, що тег мета-роботів і директива не-індексу запобігають індексування URL-адрес в Google, але не відстежують його , а це означає, що Google читає вміст і він знає, що ці сторінки присутні, але, нарешті, він не додає їх до своєї бази даних.
Однією з особливостей тегу мета-роботів є те, що він дозволяє пропонувати інформацію Google , а не лише про URL-адреси, які ви хочете індексувати, чи про внутрішні посилання, зображення або будь-який тип файлу .
Що вказує на кожну з цих позначок?
Немає індексу, щоб URL не індексувався.
Індекс використовується для індексування URL-адреси.
Використовувати не слід, щоб не передавати повноваження до посилань, які вони мають у внутрішній URL-адресі.
Слідкуйте за тим, щоб він передав повноваження. У коді ми будемо грати з індексом і слідувати, як він показує, цей приклад html тега мета роботів :.
Залежно від наших інтересів, ми будемо грати з різними комбінаціями ярликів. [Додаткова інформація у розділі "Питання та відповіді" на тему Robots.txt та мета-роботи)
Практичні приклади [хвилин 3:00]
Тепер з комп'ютером спереду ми побачимо деякі практичні приклади як robots.txt, так і тега мета-роботів.
Як приклад ми беремо веб-сторінку Zalando.es і бачимо її вихідний код. Якщо натиснути на комбінацію клавіш "Control + F", то знайдемо роботів. Наприклад, в даному випадку, у будинку, який ви маєте в індексі, слідуйте. Ми можемо зробити це більш візуально Розширення Google Chrome для SEO як Seerobots ,
Не вводячи вихідний код, він повідомляє нам, що таке індекс, наступний на цій сторінці.
Ми працюємо більшу частину часу з Крик , один з найпотужніших інструментів для імітації того, як движок Google сканує наш сайт.
Просто, ви повинні відкрити Screaming Frog, вставити Zalando.es і він почне відслідковувати його.
Ми не будемо чекати його повної сканування, тому що це нескінченна павутина, але ми дозволяємо їм відстежувати кілька URL-адрес, і ми зупинимося, щоб побачити, чи бачимо ми відмінності між індексом та індексом.
Screaming Frog ділить все, що ми знаходимо в стовпці, і будемо шукати стовпець мета-роботів. Ми можемо взяти його до початку, якщо ми хочемо працювати з ним більш комфортно.
Аналіз мета-роботів з кричущою жабою [хвилина 4:56]
Ми бачимо, що мета-роботи з'являються ліворуч, а потім URL-адреси.
Таким чином, ми бачимо, які сторінки зазвичай містять мітку No Index у мета-роботах:
Всі ці сторінки мають не індекс, оскільки вони не цікаві для позиціонування пошукової системи . Однак, вони повинні мати параметр Follow , щоб вони могли передавати повноваження по зв'язках, які вони мають.
Наприклад, у Zalando ми бачимо, що він має як No Index деякі категорії або розміри, можливо, тому, що він усунув їх. Це буде залежати від випадку вашого сайту, ми можемо працювати так чи інакше.
Якщо ми збираємося використовувати повний екран всередині Google, я виявив, що, роблячи сайт: zalando.es inurl: size "s , ми бачимо всі URL, які Zalando має зі статтями розміру S.
Якщо ми відкриємо їх, ми побачимо, що Див.
Що таке Zalando? Під час підготовки цього міні-курсу я виявив, що цей тип URL-адреси не містить індексу, а потім блокує його за допомогою robots.txt.
ВАЖЛИВО: Перш ніж блокувати що-небудь у файлі robots.txt, воно має бути деіндексировано . Чому? Тому що якщо ми заблокуємо перед вставкою No Index в мета-роботах, він не буде проіндексований, тому що Google не зможе відстежувати його та деіндекувати його правильно.
Приклади Robots.txt [Хвилина 6:26]
Будь-який цікавий приклад robots.txt? Королівський будинок, я думаю, ви будете знати. Якщо ми подивимося, ми побачимо, що пан Урдангарін був заблокований.
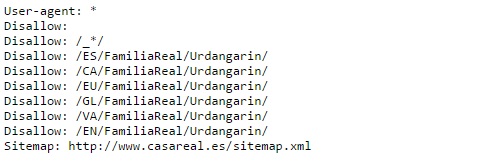
Vodafone використовували його, щоб дати деяку рекламу. Роботи дають вам певну вірусну точку, щоб прокоментувати його пізніше в блогах.

FAQ'S ПРО РОБОТА.TXT І METAROBOTS

# 1 - Як створити файл Robots.txt?
Для створення файлу robots.txt можна використовувати блокнот вашого комп'ютера, де вам доведеться вставити відповідний вміст, який буде вказувати Google шлях, який повинні виконувати ваші боти.
User-agent: [павук ім'я / бот Google]
Заборонити: [каталог або файл]
Дозволити: [каталог або файл]
Мапа сайту: [URL-адреса Sitemap XML]
Агент користувача посилається на офіційну назву, отриману роботом Google (Googlebot, googlebot-image, googlebot-mobile тощо)
Команда "disallow " вказує на той вміст, який ми не хочемо індексувати, а "дозволити" - навпаки.
І з командою " sitemap " ми показуємо Google URL нашого Sitemap XML, допомагаючи йому швидше індексувати.
Якщо ви хочете дізнатися файл robots.txt будь-якого веб-сайту, вам просто потрібно ввести відповідну URL-адресу, що супроводжується командою /robots.txt → www.example.com/robots.txt.
# 2 - Які комбінації мета-роботів можна зробити?
За допомогою тега мета-роботів ви можете робити різні комбінації залежно від того, як ви хочете, щоб Google діяв:
Індекс, наступне: Таким чином, ви повідомляєте Google, що ваші боти будуть сканувати, а потім індексувати сторінку →.
No Index, Follow : За допомогою цієї комбінації можна уникнути індексації, але відстеження дозволяється. Це найбільш ефективний варіант, якщо ви хочете, щоб певна сторінка не відображалася в результатах пошуку →.
Index, No Follow : Дозволяє індексувати URL-адресу, а не її відстеження. Ця комбінація рекомендується, якщо у вас є сторінка з посиланнями, які ви хочете залишити непоміченими для Google →.
No Index, No Follow : Уникають як індексація, так і відстеження →.
Якщо ви працюєте з CMS, ми рекомендуємо вам використовувати плагін, який дозволяє вам правильно налаштувати його, наприклад, Yoast SEO або SEO Ultimate.
# 3 - Отже, яка велика різниця між Robots.txt і мета-роботами?

Основна відмінність між обома елементами полягає в тому, що, хоча файл robots.txt повідомляє ботам сторінки, які вони не повинні відстежувати , мета-робот тег дозволяє відстежувати сторінки, але не індексування .
З обома варіантами, сторінки повинні бути повністю невидимими в Google SERP, але при блокуванні з robots.txt буде блокувати як сторінку, так і будь-яку посилання, включені в цю сторінку, якщо ви виберете мета-роботів, сторінка не буде проіндексована, але буде відслідковувалися , дотримуючись шляху посилань, які включили і передали значення цих посилань.
Якщо взяти до уваги, що Google посилається на посилання для переходу від однієї URL до іншої, ми бачимо очевидну перевагу в тезі мета-роботів , оскільки вона надає вам можливість уникати індексування потрібних сторінок, не стаючи їх перешкода для пошукових систем при скануванні нових сторінок.
З іншого боку, robots.txt є більш ефективним, ніж мета-робот-тег, коли йдеться про блокування повноцінних каталогів , тому що для роботи не потрібно мати доступ до сторінки, щоб дізнатися, чи слід сканувати її, дозволяючи набагато швидше читати і що Під час кожного візиту робота можна простежити більшу кількість сторінок.
Ключ до успіху полягає в тому, щоб знати, як поєднати обидві методи , блокування з robots.txt і використання тега мета-роботів для всього, що ми не можемо покрити файлом протоколу виключення робота.
Висновок
Тут ви маєте дві основні поняття в веб-оптимізації, тому що завдяки файлу robots.txt ми можемо запобігти скануванню сторінки до бота Google, але не індексації. Зі свого боку, тег мета-роботів запобігає індексування URL-адреси, але не його сканування, тому ця сторінка не відображатиметься в результатах Google.
Тому, хоча обидва варіанти використовуються для запобігання появі сторінки в видачах великої пошукової системи, кожен з них діє конкретно, отже, необхідно знати її природу і вибирати найкращу альтернативу відповідно до наших цілей.
Ми сподіваємося, що і відео, і стаття допомогли вам побачити світло в кінці тунелю цих двох концепцій, які настільки схожі, але різні одночасно.
У вас є сумніви? Залиште ваші коментарі нижче.
Txt?
Txt?
Що таке мета-роботи?
Txt і мета-роботами?
Txt?
Txt?
Що таке мета-роботи?
Що вказує на кожну з цих позначок?
Що таке Zalando?
Чому?