- Вплив алгоритму на запити різних типів
- Порівняння: Яндекс versus Google
- Значимість для SEO
- Технічна реалізація
- Подальший розвиток підходу
- Корисні посилання
Штучна нейронна мережа з прихованими шарами, «довгий хвіст», додатковий індекс і пошук з урахуванням семантичного відповідності ( «сенсу»).
Хм, серйозно? Разом розбираємося з новим алгоритмом Яндекса.

У другій половині серпня Яндекс запустив новий алгоритм під назвою «Корольов». Офіційний анонс відбувся 22 серпня 2017 року блозі Яндекса для вебмайстрів [1] і в блозі на Хабрахабр [2]. Реальні ж зміни видачі - були помітні і раніше, завдяки аналізатору апдейтів видачі «Піксель Тулс».
Основне завдання: поліпшення якості видачі по багатослівним низькочастотних запитах, по яким якість видачі було низьким (свідомо гірше, ніж у Google - основного конкурента в рунеті). В даний сегмент фраз часто потрапляють і голосові запити, задані з переносних пристроїв на природній мові (зростаючий попит).
Що відрізняє даний алгоритм «Корольов» від попереднього «Палеха» [3]? Додавання в загальний набір факторів ранжирування, які враховують:
Схожість того «сенсу», який прихований в пошуковій фразі і «сенсу» всього документа, а не тільки заголовка вікна браузера Title .
Якість відповіді документа на схожі за «змістом» запити користувачів.
Нова технічна реалізація з розрахунком ряду факторів на етапі індексування і впровадженням додаткового індексу (див. Нижче).
Щоб зрозуміти, який сенс * вкладає користувач в пошуковий запит і який сенс розкривається в тексті сторінки - використовується нейронна мережа. Тобто, нейронна мережа як один з методів машинного навчання, лежить в основі обчислення ряду нових факторів, які далі використовуються в алгоритмі ранжирування.
* - далі ми будемо вживати це слово без лапок, але важливо розуміти, що «сенс», який обчислюється за допомогою комп'ютерного алгоритму і реальний сенс, який вкладає в запит / документ автор - нееквівалентні поняття.
Вплив алгоритму на запити різних типів
В першу чергу, «Корольов» зачіпає ранжування по довгих і / або рідкісним пошуковим запиту, які часто задаються на природній мові. Приклад: [фільм де людина біжить з в'язниці після дуже довгої відсидки].
З точки зору SEO-класифікації це НЧ-і МНЧ-запити , Як правило, інформаційні, але можливих і комерційні варіанти, скажімо: [купити штуку яка крутиться на пальцях]. Саме цей сегмент пошукових фраз носить назву «довгого хвоста». На нього припадає понад 34% запитів з потоку.
На поточний момент, для ряду запитів, за якими нова група факторів отримала високу значимість, але пошукова система не до кінця впевнена в коректності його застосування - проводиться анкетування користувачів (Рис. 1).
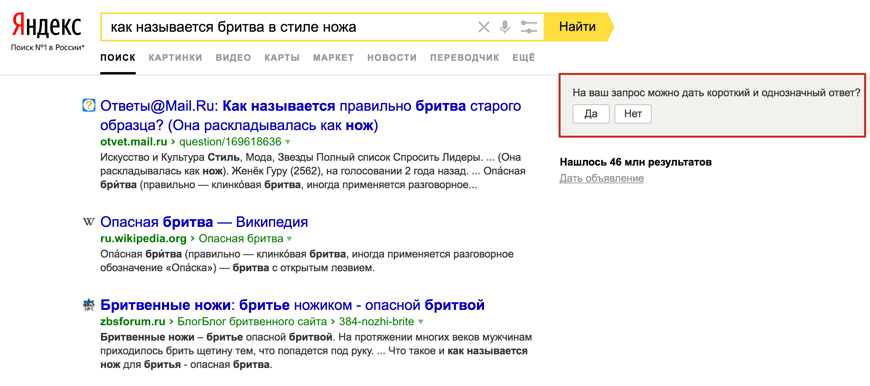
Мал. 1. Яндекс уточнює у користувача, чи коректно була підвищена значущість нової групи факторів для запиту
[Як називається бритва в стилі ножа], яку відповідь за питання є правильним і де він був знайдений?
Порівняння: Яндекс versus Google
Із запитом, який наведено вище - Google справляється куди краще, ніж Яндекс (Рис. 2), але репрезентативна чи це картина? Для відповіді на це питання - вибірка була збільшена і проведена ручна оцінка якості видачі по кожному з 127 запитів в режимі «Інкогніто». Початковий файл в TXT-форматі , Роздільник між колонками - крапка з комою. дані зібрані Вікторією Левеня ( «Піксель Плюс») через 3 дні після офіційного анонсу.
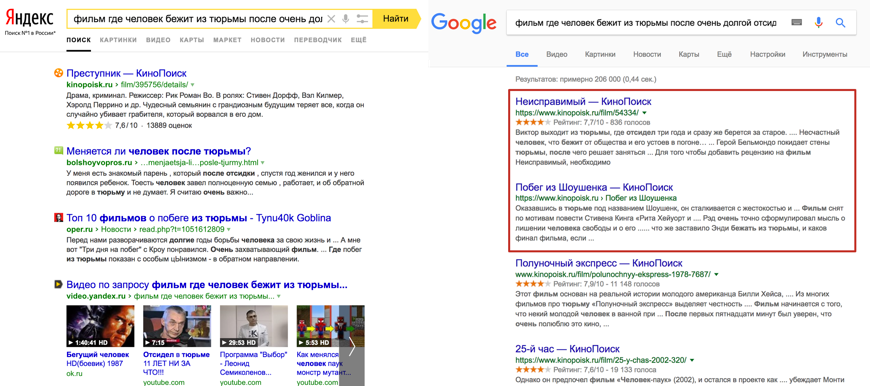
Мал. 2. Порівняння якості видачі Яндекса і Google за запитом [фільм де людина біжить з в'язниці після дуже довгої відсидки].
В результаті аналізу SERP двох пошукових систем по пулу запитів, можна зробити наступні висновки:
Якість відпрацювання алгоритмів «Корольов» та «RankBrain» - є порівнянним.
У більшості випадків (близько 70% з вибірки) - SERP виявляється схожим за якістю, що може говорити про близькість самих алгоритмів реалізації (нагадаємо, що «RankBrain» був запущений в Google в жовтні 2015 року).
Частка запитів, для яких алгоритмам вдається успішно вгадувати сенс, заданого на природній мові становить близько 80% з вибірки (повнота).
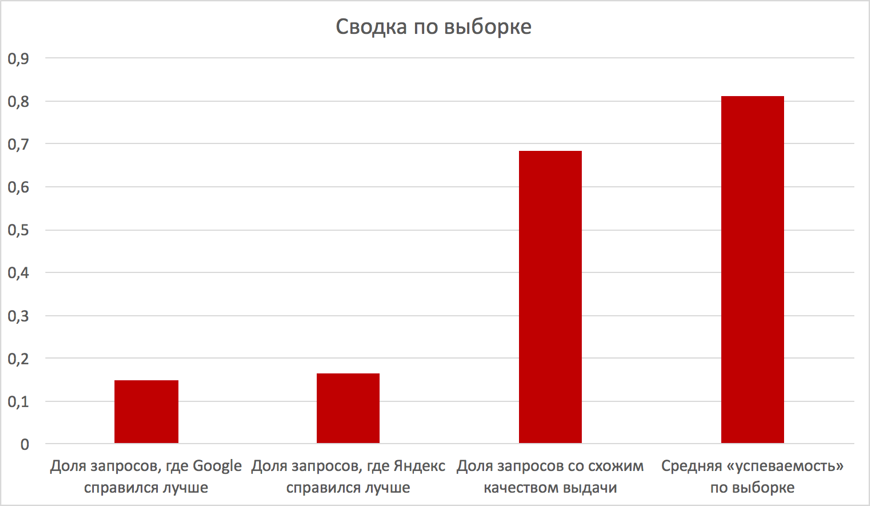
Мал. 3. Підсумкові показники роботи алгоритмів Яндекса і Google за вибіркою МНЧ-фраз.
Значимість для SEO
Як позначається новий алгоритм ранжирування Яндекса на пошукової оптимізації (SEO)? Фактично, найбільш значущі зміни спостерігаються лише для фраз, за якими немає достатньої кількості релевантних відповідей з класичної точки зору (немає сторінок з точними входженнями фраз і високою частотою зустрічальності термів). Це означає, що ранжування по частотним запитам, за якими просувається більшість комерційних проектів зазнає мінімальних змін за рахунок вкладу нової групи чинників.
Як показує практика, значно частіше точне входження ключової фрази (якщо воно є) «перемагає» вклад нової групи чинників в ранжування. Для прикладу розглянемо запит [лінива кішка з Монголії], який згадувався в презентації алгоритму як один з тих, за яким «Корольов» допомагає знайти короткий і правильну відповідь - манула.
На ілюстрації нижче (Рис. 4) видно, що хоча алгоритм і вгадує сенс фрази (об'єктний відповідь справа [4]), але вище в SERP виявляються документи з входженнями слів із запиту і точним входженням в тексті (ті ж анонси), що наочно підтверджує гіпотезу. Це одна з причин, по якій приклади, які публічно анонсують для ілюстрації відпрацювання алгоритму перестають «працювати» після прес-релізу.
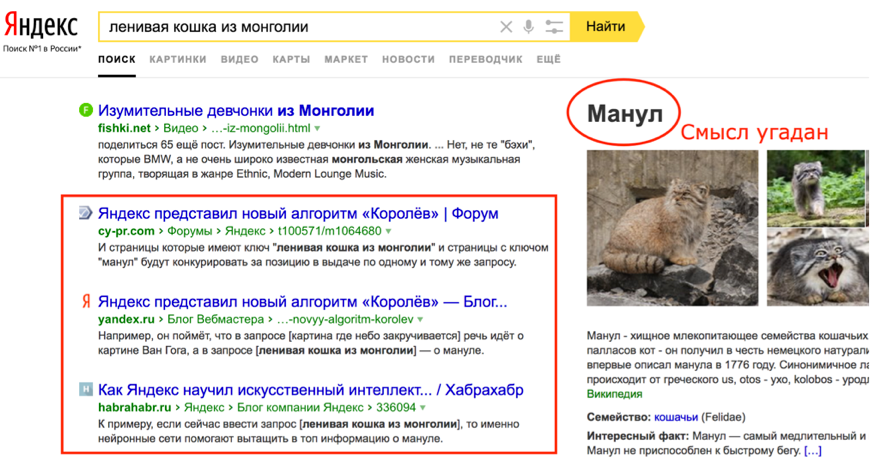
Мал. 4. Поточний «зламаний» вид SERP Яндекса за запитом з презентації.
Разом: якщо SEO-фахівець провів роботи по поліпшенню «класичних» факторів ранжирування , То URL буде добре ранжируватися по потрібної НЧ-фразі. Тут революції немає.
У комерційному ранжируванні, при інших рівних, нова група факторів, звичайно, може вносити якийсь внесок в ранжування. Для поліпшення значень по ній використовуються прийоми LSI-копірайтингу .
Технічна реалізація
Для прискорення формування відповіді на запит користувача, використовується не тільки підсумкова формула ранжирування. Є кілька етапів, кожен з яких відбирає претендентів для наступного, більш «важкого» алгоритму (Рис. 5).
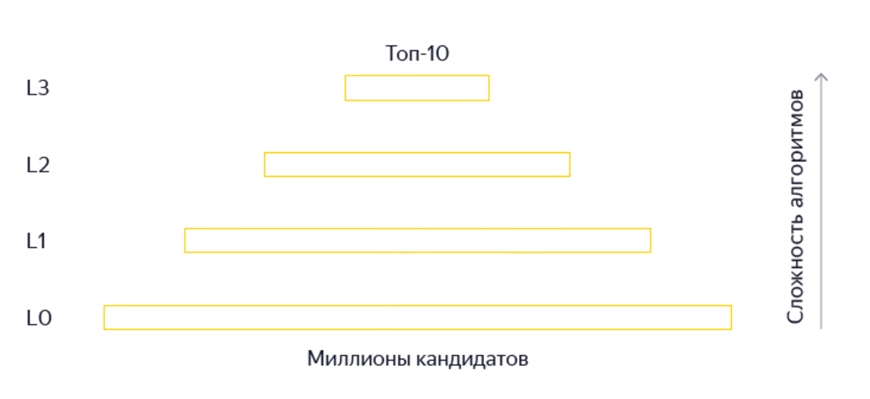
Мал. 5. Етапи ранжирування в пошуковій системі Яндекс (фільтрація / кворум , Fast Rank, моном або часткове виконання Матрикснет і підсумкова формула релевантності).
Так як обчислення сенсу для великого числа текстів на льоту є тривалою завданням, то даний процес був зміщений з фінальної стадії ранжирування (як було в «Палеху») на етап індексування.
Для прискорення фінальної стадії ранжирування і звільнення обчислювальних ресурсів був введений додатковий індекс, який містить вже обчислену інформацію про «орієнтовною» релевантності всіх документів для всіх одиночних слів і популярних пар слів, які зустрічаються в запитах користувачів. Даний крок дозволив вивільнити для пошуку обчислювальні потужності, які необхідні для відпрацювання складних моделей, заснованих на нейронних мережах (новий набір факторів).
Навчання нейронної мережі вироблялося спираючись на численні асессорскіе оцінки і поведінку користувачів. Нагадаємо, що для збільшення загального числа оцінених пар запит-документ, Яндексом був запущений публічний сервіс «Толока» [5], який дозволив кратно збільшити число асессоров і самих оцінок (Рис. 6).
Мал. 6. Зовнішній вигляд сервісу Яндекс.Толока для виконавця завдань (асесора).
Друга причина причина по якій приклади, які публічно анонсують перестають «працювати» складається саме в різкій зміні паттерна поведінки користувачів по ним і зростанні їх популярності.
Подальший розвиток підходу
Машинне навчання використовується в пошуку Яндекса для побудови формули ранжирування починаючи з 2009 року [6]. Підсумкова формула і зараз формується завдяки методу Матрикснет, але ряд факторів в ній є «непростими» і самі отримані за допомогою нейронних мереж (машинного навчання). В якомусь сенсі - матрьошка.
Надалі планується:
Поліпшення якості оцінки семантичної відповідності (сенсу) запиту і сторінки.
Підвищення повноти відпрацювання.
Зміна логіки фільтрації документів на стартовому етапі L0 (Рис. 5) - проходження кворуму .
Додавання до моделі вектора персональних інтересів користувача ( персоніфікація видачі ).
Разом стежимо за розвитком подій!
Корисні посилання
Пошук, який ми робимо разом 2017, https://yandex.ru/blog/company/korolev
Як Яндекс навчив штучний інтелект розуміти сенс документів 2017, https://habrahabr.ru/company/yandex/blog/336094/
Всі алгоритми Яндекса по роках, хронологія 2007-2017, 2016-2017, https://pixelplus.ru/samostoyatelno/stati/prodvizhenie-saytov/algoritmy-ranzhirovaniya-yandex.html
Об'єктний відповідь, 2015-го, https://yandex.ru/company/technologies/entity_search/
Яндекс.Толока, 2014 року, https://toloka.yandex.ru/
Матрикснет 2009, https://yandex.ru/company/technologies/matrixnet
Хм, серйозно?