Анализ файла журнала помогает понять, как поисковые системы сканируют сайт и как они влияют на SEO. Получаемая информация является отличным помощником в улучшении вашей способности сканировать и производительности SEO.
С помощью этих данных вы можете проанализировать поведение сканирования и выявить интересные метрики, такие как:
- Ваш бюджет обхода расходуется эффективно?
- Какие ошибки, связанные с доступностью, были обнаружены во время сканирования?
- Где находятся зоны дефицита сканирования?
- Какие самые активные страницы?
- Какие страницы Google не знает?
Дело в том, что вы также можете сделать этот анализ бесплатно. OnCrawl, таким образом, обеспечивает анализатор логов с открытым исходным кодом ,
Это поможет вам обнаружить:
- Уникальные страницы, отсканированные Google
- Частота сканирования по группам страниц
- Кодовые статусы
- активные и неактивные страницы
Как это работает?
1- Установите Docker
устанавливать Ящик для инструментов Docker ,
Выберите терминал Docker Quickstart, чтобы начать.
Скопируйте и вставьте IP-адрес 192.168.99.100 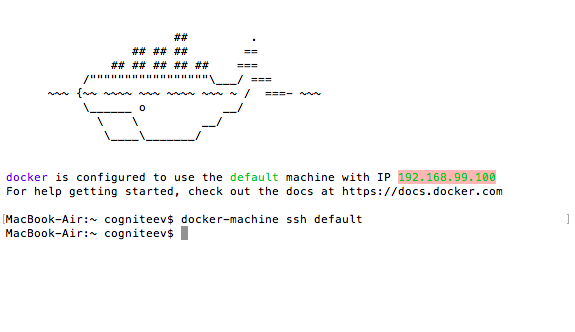
Затем загрузите публикацию oncrawl-elk: https://github.com/cogniteev/oncrawl-elk/archive/1.1.zip
Добавьте эти строки в терминал, чтобы создать каталог и разархивировать папку:
- MacBook-Air: ~ cogniteev $ mkdir oncrawl-elk
- MacBook-Air: ~ cogniteev $ cd oncrawl-elk /
- MacBook-Air: oncrawl-elk cogniteev $ unzip ~ / Downloads / oncrawl-elk-1.1.zip
И затем добавьте:
- MacBook-Air: oncrawl-elk cogniteev $ cd oncrawl-elk-1.1 /
- MacBook-Air: oncrawl-elk-1.1 cogniteev $ docker-compose -f docker-compose.yml up -d
Docker-compose загрузит все необходимые образы из Docker Hub, так что это займет несколько минут. После запуска контейнера докера вы можете ввести в браузере следующий адрес: HTTP: // IP-DOCKER: 9000 , Будьте осторожны, чтобы заменить DOCKER-IP на тот IP, который вы скопировали ранее.
Вы должны увидеть панель мониторинга OnCrawl-ELK, но без данных. Поехали и поищем данные для анализа.
2-Импорт файлов журнала
Импортировать данные так же просто, как копировать файлы доступа к журналу в нужную папку. Logstash начнет автоматически индексировать любой файл, найденный в logs / apache / *. Log, logs / nginx / *. Log.
Если ваш веб-сервер работает на Apache или NGinx, убедитесь, что формат адаптирован к формату журнала. Это должно выглядеть так:
127.0.0.1 - - [28 / Aug / 2015: 06: 45: 41 +0200] "GET /apache_pb.gif HTTP / 1.0" 200 2326 "http://www.example.com/start.html" "Mozilla / 5.0 (совместимо; Googlebot / 2.1; + http: //www.google.com/bot.html) "
Перетащите свои файлы журналов в logs / apache или в каталог logs / nginx соответственно.
3-Play!
Вернуться на http: // DOCKER-IP: 9000. Теперь у вас должны быть цифры и графики, поздравляю!
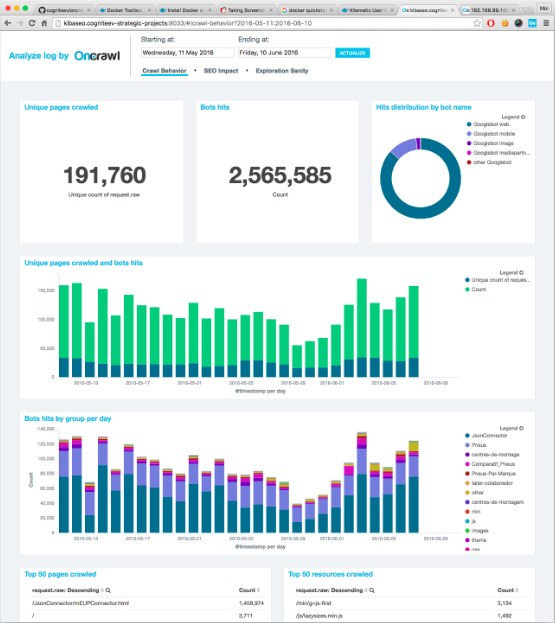
Вы также можете объединить эти данные с вашими данными сканирования и получить доступ к полному представлению о своей эффективности SEO. Вы также сможете обнаружить активные потерянные страницы, проверить коэффициент сканирования по глубине или группе страниц и другую интересную информацию. Чтобы узнать больше о перекрестном анализе, вы можете взглянуть на это страница ,
Какие ошибки, связанные с доступностью, были обнаружены во время сканирования?Где находятся зоны дефицита сканирования?
Какие самые активные страницы?
Какие страницы Google не знает?